I called it a shootout first, but hey, it wasn’t anything violent.
Sensing temperature with Python and the pyboard
Because I have the best spouse in the world, my recent birthday brought me a whole pile of little boxes with electronic tinker toys, useful ones, straight from Hackerboxes. I’ve since been renewing my acquaintance with the soldering iron and dusted off an old project about building environmental sensor units.
One of the development boards I was keen to try out is the pyboard, which is the original or official board for MicroPython. MicroPython is a new implementation of a remarkably rich subset of Python 3.4 to run on microprocessors. I already had a good deal of experience with CircuitPython, the education-friendly derivative of MicroPython published and maintained by Adafruit. Now it was time for the real thing.

So the plan I came up with is: Gather the temperature sensors from my kit, hook them all up to the pyboard at the same time, log the temperature for a while and compare the outcome.
The sensors
After rummaging through my component boxes, I fished out these three sensors (pictures below):
- The TMP36 is a popular low-cost silicon band gap temperature sensor. It is small, with three output pins, and comes in a black plastic housing. T range: -40-150 °C, T accuracy ±2 °C. Price: $ 1.50
- The DHT11 is a very common temperature and relative humidity sensor with not the best reputation for accuracy. It comes in a blue housing with electronic components included, and our version (from a Hackerbox) is mounted onto a small board, which adds a pull-up resistor and a power LED. The DHT11 documentation is a little spotty. The sensor apparently uses a negative temperature coefficient (NTC) thermistor (ie, temperature goes up → resistance goes down) and some kind of resistive humidity measurement. The sensor can only take T measurements every 2 sec. T range: 0-50 °C, T accuracy ±2 °C, RH accuracy ± 5%. Price: $ 5
- The most expensive item in this set, the Sensiron SHT31-D, uses a CMOS chip to measure temperature and relative humidity, with a capacitive method. I used the lovely little Adafruit breakout board. T range: -40-125 °C, T accuracy ±0.3 °C (between 0 and 60 °C) and up to ±1.3 °C at the edges, RH accuracy ± 2%. Price: $ 14.
The prices are 2018 prices from US vendors. By ordering directly from Chinese outlets, you can usually reduce them to ~40%, except for the much rarer SHT31-D, for which only one ready-to-use alternative (which is not much cheaper) appears to exist.


Communication protocols, libraries, and code
All code, both on the computer side and the pyboard side, is available in a git repository on GitHub.
Two related consideration at this stage: What communication protocol do the sensors use, and what MicroPython libraries are available to drive them from the pyboard?
While the documentation for MicroPython is superb, I found the pyboard to be a lot less well documented. MicroPython comes with a library specific to the pyboard (pyb) as well as generic libraries that are supposed to work with any supported board (eg. machine), and their functions sometimes overlap. I had to consult the MicroPython forum a few times to figure out the best approach.
- The TMP36 is a single-channel analog sensor: The output voltage is linear in the temperature (it boasts a linearity of better than 0.5%). So we need a DAC pin to measure the output voltage at the pyboard (using a DAC object from the pyb module). According to a forum post, the pin output is a 12-bit integer (0-4095) that is proportional to the voltage (0-3.3V). So we get the voltage in mV by multiplying the pin value by 3300 and dividing by 4095. Then, as per the TMP36 datasheet, we have to subtract 500 and divide by 10 to convert that value to °C. Easy.
- The DHT11 also uses single channel protocol, but a digital one, which looks a little idiosyncratic. (I was a little surprised to find that none of my sensors uses the popular 1-Wire bus.) Luckily, MicroPython ships with a library (dht) that takes care of everything. It outputs temperature in °C and relative humidity in %.
- The SHT31-D communicates via an I2C bus. I used MicroPython’s generic machine module and sht31 module provided by kfricke that builds on it.
I was particularly happy how easy it is to scan the I2C bus for the device port with MicroPython. From the MicroPython REPL (which you enter to as soon as you connect to a new pyboard via a terminal emulator like screen), it’s great to be able to create and probe objects interactively, for example like so:
>> import machine
>> SCLpin = 'X9'
>> SDApin = 'X10'
>> i2c = machine.I2C(sda=machine.Pin(SDApin),
scl=machine.Pin(SCLpin),
freq=400000)
>> i2c.scan()
This said, the sht31 library doesn’t even need the user to provide the port. I’m just noting this because this task can be a little frustrating on the Arduino platform, and take more tries to get it done.
Our basic workflow was this:
- Using the MicroPython REPL, develop the MicroPython code incrementally. The goal is to take a measurement every 10 sec and send the data back to the computer over the USB serial port.
- Upload finished MicroPython code to the pyboard.
- Use the USB connection now to receive serial data from the pyboard (using Python 3 on the computer) and also to power the board.
- Let the assembly collect data for a few hours and write it to a file.
- Visualize the data afterwards.
I let the experiment run for a few overnight hours in my somewhat overheated home office corner, where the air is very dry.
The measurement results
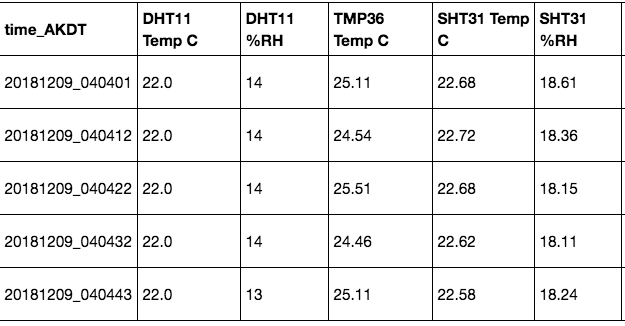
Even while monitoring the data flow, some observations stand out: The DHT11 only provides temperatures in whole degrees. And the temperature measured with the TMP36 is a good bit (about 2-3 °C) higher than the output from the other two sensors. The data looks somewhat like this:
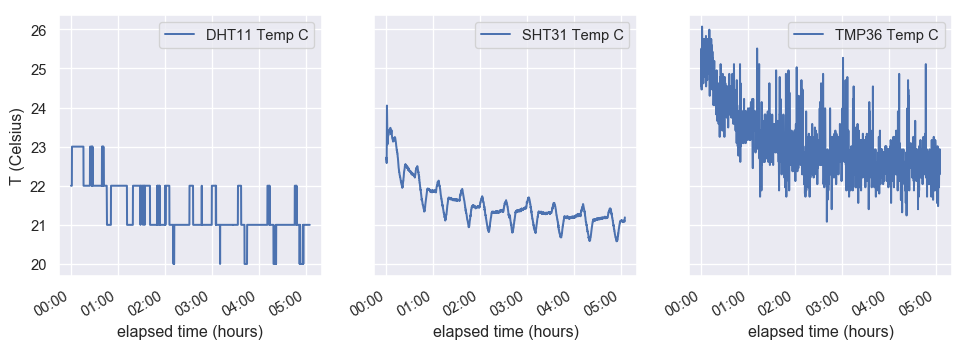
Let’s look at plots of the three temperature curves. At first, I was not impressed: The DHT11 measurements seemed to jump around a whole lot, the SHT31 has a very weird periodic signal and the TMP36 data is incredibly noisy (apart from unrealistically high – the room wasn’t that badly overheated!).
But things become clearer once we plot onto a single figure: The upticks of the DHT11 measurement correspond exactly to the peaks of the SHT31 data, and so do the minima! Also, the two sensors agree, within their precision, quite well in absolute value. Once I took the SHT31 signal seriously, I realized what it was due to: The thermostat cycle of our Toyo oil stove! I had no idea that it was on this 30 min cycle. How interesting. And now that I know, I really like the SHT31. (Apparently you get what you pay for in this case.)
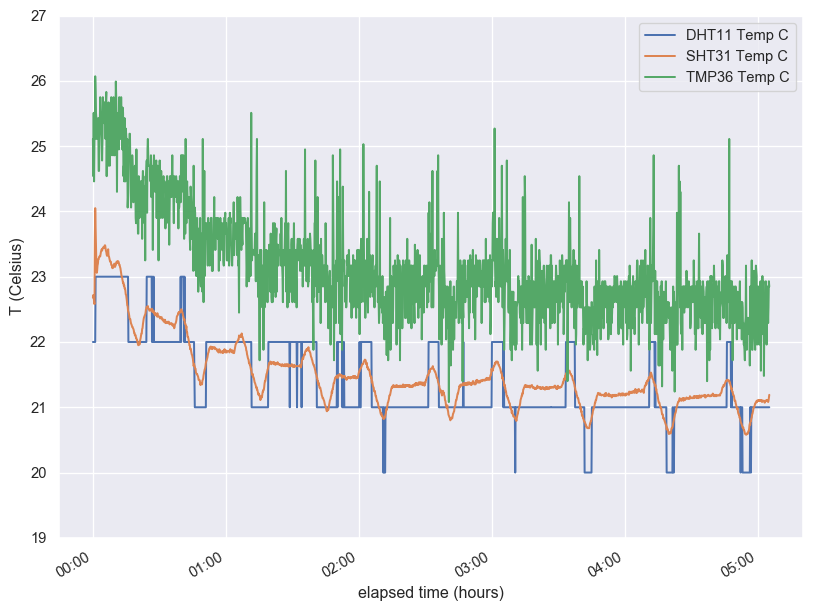
What about the TMP36? Well, it’s noisy and operating way outside its nominal accuracy, but at least some of the signal is clearly due to the real temperature variation.
The fall-off of the data during the first hour is, btw, probably because I removed my body from the desk and went to bed. The air cooled afterwards.
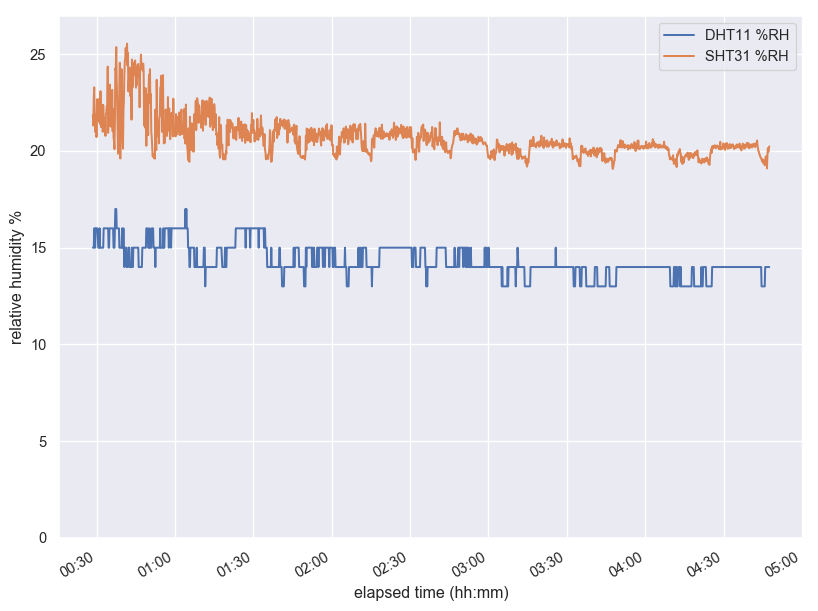
Since I had the relative humidity data, I looked at it, too. Here the SHT31 and the DHT11 agree less well in absolute value, and I think the latter is in agreement with its reputation as not very accurate. I find the SHT31 values a lot more convincing. One thing that the graphs don’t show is that if you blow on the sensor, the SHT31 adjusts immediately and goes back to normal pretty fast, while the DHT11 takes a few seconds for its measurement to jump. It also saturates quickly (showing unrealistic nearly-100% of RH) and takes a long time to return from an extreme measurement.
What did we learn? What else could we find out?
So this was interesting! I didn’t expect to get so clear a feeling for the different sensors’ strengths and weaknesses. At the same time, I’m have more questions…
- The DHT11 confirmed its reputation as a very basic sensor. Its temperature measurement was in better agreement with what I think is reality than expected, but the relative humidity is not very trustworthy. Its limited range and whole-degree step size make it a mediocre choice for a personal weather station, and its slowness unsuitable for, say, monitoring temperature sensitive circuitry. But could we get a higher resolution with a different software library? Are there settings that escaped my notice? As-is, I see its application mostly in education and maybe indoors monitoring when you don’t need much precision.
- The TMP36 was disappointing, but maybe my expectations of this $ 1.50 sensor were excessively high. As an analog sensor, it is faster than the DHT11 (though I don’t know how fast … just yet) and can be used for monitoring temperature extremes, but not with high precision because of the noise! Maybe a good approach would be to reduce the noise in some fashion. Also, did I have a bum unit, or do they all need calibrating? Maybe the pyboard-specific conversion formula has a flaw, and a different board or method would produce a different result?
- The SHT31-D looks like a great sensor all around. Also congratulations to Adafruit for producing an outstanding breakout board. This would be my choice for a weather station, hands down.
Other questions I have are: How different would the performance be in a different temperature range? I live in Alaska, and temps went down to -30 °C today. (My medium-term plan is to put a sensor under the snow.) Also, how fast can we actually retrieve successive measurements from our two faster sensors? Last, I think I found at least two more temperature sensors in my kit. How do they compare?
I think there might be a part 2 in the works…